








OCR e ICR le nuove frontiere di digitalizzazione del testo
OCR, quando la scrittura diventa digitale
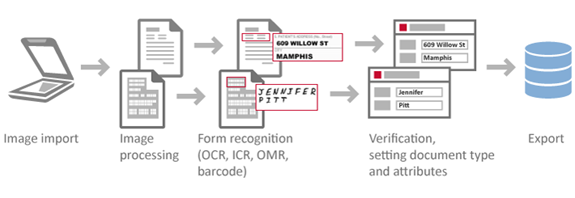
Il sistema di riconoscimento ottico dei caratteri, OCR (optical character recognition), è una tecnica algoritmica usata per rilevare i caratteri contenuti in un documento e trasferirli in un testo digitale.
L’acquisizione può essere fatta attraverso un qualsiasi mezzo fisico che consenta di acquisire immagini, generalmente tramite scanner oppure fotocamere o videocamere.
Ray Kurzweil, nel 1947, ha sviluppato il primo software OCR omni-font in grado di riconoscere il testo stampato.
I software OCR per funzionare correttamente richiedono una fase di “addestramento”. Il sistema, in modalità non supervisionata, impara a classificare e riconoscere i caratteri che gli vengono sottoposti sotto forma di immagini. Queste, vengono associate al corrispondente testo in formato ASCII o simile, in modo da calibrare gli algoritmi sul testo che andranno ad analizzare. Questa sessione di Training è fondamentale se si considera che gli elementi che analizzano il testo sono delle reti neurali e quindi richiedono un addestramento. Gli ultimi software di OCR utilizzano algoritmi che riconoscono i contorni e sono in grado di ricostruire il testo e la formattazione della pagina.
L’evoluzione del testo scritto a mano
Il riconoscimento esatto di un testo scritto in alfabeto latino ad oggi è considerato un problema risolto, con tassi di riconoscimento superiori al 99%. Il riconoscimento della scrittura a mano libera e degli alfabeti non latini è un problema ancora irrisolto e oggetto di studi e ricerche.
I Sistemi realizzati per riconoscere la scrittura a mano libera hanno avuto un discreto successo commerciale se integrati in prodotti come PDA o computer portatili. Il precursore è stato il dispositivo Newton Message Pad (OMP), creato nel 1993 dalla Newton, la famiglia di computer palmari prodotta da Apple. Negli algoritmi implementati in questi dispositivi si chiede all’utente di scrivere le lettere seguendo uno schema predefinito per ridurre i casi di ambiguità. Tuttavia il riconoscimento di testo contornato può aprire nuovi di problemi e quindi, se fatto su una scansione di testo scritto a mano, il rischio di imprecisione è superiore al 70%.
Quando si tenta di riconoscere un testo scritto in corsivo l’accuratezza del riconoscimento è inferiore anche a quella di un testo scritto a mano. Finché non si avranno informazioni aggiuntive derivate da un’analisi contestuale o grammaticale del testo non sarà possibile raggiungere livelli maggiori di accuratezza.
Pertanto, il miglioramento del livello di affidabilità rilevato da una fase di riconoscimento potrà essere indicato come confidenza, la quale può essere aumentata grazie all’implemento di strategie legate a:
- Analisi sintattiche delle parole estratte
- Analisi semantica del termine rilevato in base al contenuto semantico del contesto in cui la parola è usata
- Miglioramento della qualità dell’immagine
Quindi, con gli OCR si può trasformare il contenuto di un documento cartaceo in digitale, comprensibile e modificabile dal computer, senza il supporto umano.
I software ICR e i sistemi di riconoscimento del testo
Esiste anche una particolare evoluzione dei sistemi di riconoscimento OCR, i software ICR (Intelligent Character Recognition), ideati per l’acquisizione intelligente della modulistica. Questi permettono al sistema, in maniera autonoma, di digitalizzare i documenti cartacei come fatture, documenti di trasporto, etc.
Oltre ai sistemi di riconoscimento OCR e ICR esistono ulteriori software specializzati per soddisfare le particolari esigenze delle aziende, come ad esempio:
- Software BCR: i sistemi di Bar Code Recognition permettono il riconoscimento dei codici a barre semplici e a matrice
- Software OMR: i sistemi di Optical Mark Recognition pensati appositamente per il riconoscimento di testi complessi come quelli dei quiz a scelta multipla, con la possibilità quindi di interpretare correttamente trattini, crocette e segni di spunta.
I vantaggi dell’Ocr, per chi e per cosa?
L’insieme di questi sistemi di riconoscimento del testo può imprimere alle attività produttive un Boost. Questo è introdotto da un software che soddisfa le esigenze di qualsiasi tipo di business azzerando le necessità di data entry legate a documenti come: contratti, fatture, questionari, test, bollettini, ricette farmaceutiche, documenti di trasporto, bar code, manoscritti e ordini.
Dall’healthcare agli istituti finanziari, dall’industria manifatturiera a quella del trasporto, fino alle società governative ed educative, tutti possono trarre vantaggio da questa tecnologia. Ogni attività di acquisizione e riconoscimento di testo richiede una precisione differente: quindi ogni azienda dovrebbe scegliere l’OCR con le procedure di imaging più adatte ai propri scopi.
Riconoscimento dei singoli template
L’utilizzo di questa tecnologia è stato perfezionato da algoritmi di intelligenza artificiale che migliorano digitalizzazione e comprensione del cartaceo, fornendo i dati per l’orientamento del business futuro.
Il prototipo, in fase di analisi, consente l’identificazione automatica dei moduli, ovvero di riconoscerne la tipologia tra quelle presenti in una collezione predefinita riportando:
- Id numerico del template
- Nome del template
- Percentuale di somiglianza con il template
Ad esempio, una collezione formata da differenti classi di moduli può sottoporne alcuni ricevuti senza preordinamento alla libreria, indicarne il modello di appartenenza, ordinarli e riconoscere facilmente i documenti specifici.
Ciò consente anche di allineare il modulo con il template di riferimento per calcolare automaticamente tutte le differenze che non combaciano perfettamente:
- scostamento orizzontale e verticale
- stretch orizzontale e verticale
- differenza di orientamento
- differenze di inclinazione
- differenze di risoluzione
Così è possibile identificare le regioni di interesse di ogni modulo specifico, anche se misurate soltanto su un campione, compensando le eventuali differenze introdotte nella scansione.
Ad esempio, un’area che si trova in una certa posizione su un modulo anche se dello stesso tipo può avere diverse posizioni nei moduli acquisiti.
L’allineamento di un documento sul suo template è quindi un’operazione prioritaria ed indispensabile per realizzare qualunque applicazione di cattura dati.
Questa nuova versione della libreria è stata completamente riscritta e, contrariamente al passato, non usa la tecnologia delle reti neutrali. Quindi l’addestramento off-line diventa obsoleto, mentre l’uso dei singoli moduli e l’implementazione in ogni istante di template a set attivo possibile.